Contextual Bandits in Python with Vowpal Wabbit
Over the past few weeks I’ve been using Vowpal Wabbit (VW) to develop contextual bandit algorithms in Python. Vowpal Wabbit’s core functionality is excellent and it appears to be the industry standard for working with bandits. However, the library is not well documented and has numerous gotchas and partially-working features, especially in the Python bindings. The library overall feels like it was built by academics rather than engineers, so the documentation treats most of the core engineering tasks as trivial and not worth explaining, while frequenly linking off to 50-page long academic research papers as explanations of what the options in the library mean.
As an engineer, there’s a lot I’ve learned that I wish I knew when I first started using this library. This post is a brain-dump of what I’ve learned that’s been useful, important, or surprising for me working with this library. I hope it will be useful for others as well! the core functionality of the library is truly excellent, it just takes a bit of effort to get it into a state where it can really shine.
This post will focus on working with the Python bindings, but a most of this will apply to working with the command-line interface as well, since the Python wrapper is just a thin wrapper around the CLI. I used the --cb_explore_adf setting, which is the most complicated, least documented, and, in my opinion, most useful setting for bandits. This setting allows for picking from a different set of actions at each invocation of the library, and allows actions to have rich sets of features as well. This post will focus on using this setting, but a lot of this post will still be relevant for using other bandit settings in vowpal wabbit as well.
If you see any mistakes or places where there are misunderstandings in this post, please leave a comment and let me know! I’m still learning and will continue to make corrections and improvements to this article as I learn more.
Working with JSON Format
The default VW input format is a string format that looks like the following:
shared | UserAge:15
| elections maine SourceTV
0:3:.3 | Sourcewww topic:4
VW also supports a JSON input format, which would look like the following:
{
"UserAge": 15,
"_multi": [
{ "_text": "elections maine", "Source": "TV" },
{ "Source": "www", "topic": 4, "_label": "0:3:.3" }
]
}
I went with the JSON format since it feels more structured, but this has been hard since this format isn’t super well documented. This JSON format is only valid JSON for individual examples. If you want to use it for more than a single example, you need to concat JSON examples with newlines between them, NOT use a JSON array, as you would probably expect. For example:
Correct:
{
"User": ...
"_multi":[...]
}
{
"User": ...
"_multi":[...]
}
{
"User": ...
"_multi":[...]
}
Incorrect:
[
{
"User": ...
"_multi":[...]
},
{
"User": ...
"_multi":[...]
},
{
"User": ...
"_multi":[...]
}
]
This was a surprise, because the “correct” way to use the JSON format here is to not actually valid JSON! Also, if you use this format you need to pass the --json param to VW.
There’s another json format called --dsjson. This is even less documented than the --json format, so I wasn’t able to figure out how to use it.
If you want to use the JSON format in python, you need to pass the JSON to VW as a JSON-encoded string, not a Python dict. So something like the following:
import vowpalwabbit
import json
vw = vowpalwabbit.Workspace("--cb_explore_adf --json")
example = {
"UserAge":15,
"_multi":[
{"_text":"elections maine", "Source":"TV"},
{"Source":"www", "topic":4, "_label":"0:3:.3"}
]
}
vw.learn(json.dumps(example))
Namespaces
You should put all your features into namespaces rather than on the top level, since this lets you make your model more powerful with the --quadratic and --cubic options as we’ll see later. For instance, below we put shared features into a namespace called “User”, and action features into a namespace called “Action”, although you can have multiple shared and action-level namespaces if you want. In JSON, this looks like the following:
{
"User": { "age": 15 },
"_multi": [
{ "Action": { "_text": "elections maine", "Source": "TV" } },
{ "Action": { "Source": "www", "topic": 4 }, "_label": "0:3:.3" }
]
}
Note: the _label property appears outside of the namespace for the action that was chosen.
I was originally pretty confused by the format of _label for --cb_explore_adf. The label has 3 components, the action number, the cost, and the probability that this action was picked by the policy that generated the data. For --cb_explore_adf, the action number is meaningless, so just write 0 ¯\_(ツ)_/¯.
Model Architecture
VW will hash all your features into a large number of buckets (2^18 by default), and learns a weight for each bucket. Then, it just sums the weights of each bucket together to get a score for the action. This is demonstrated in the diagram below.
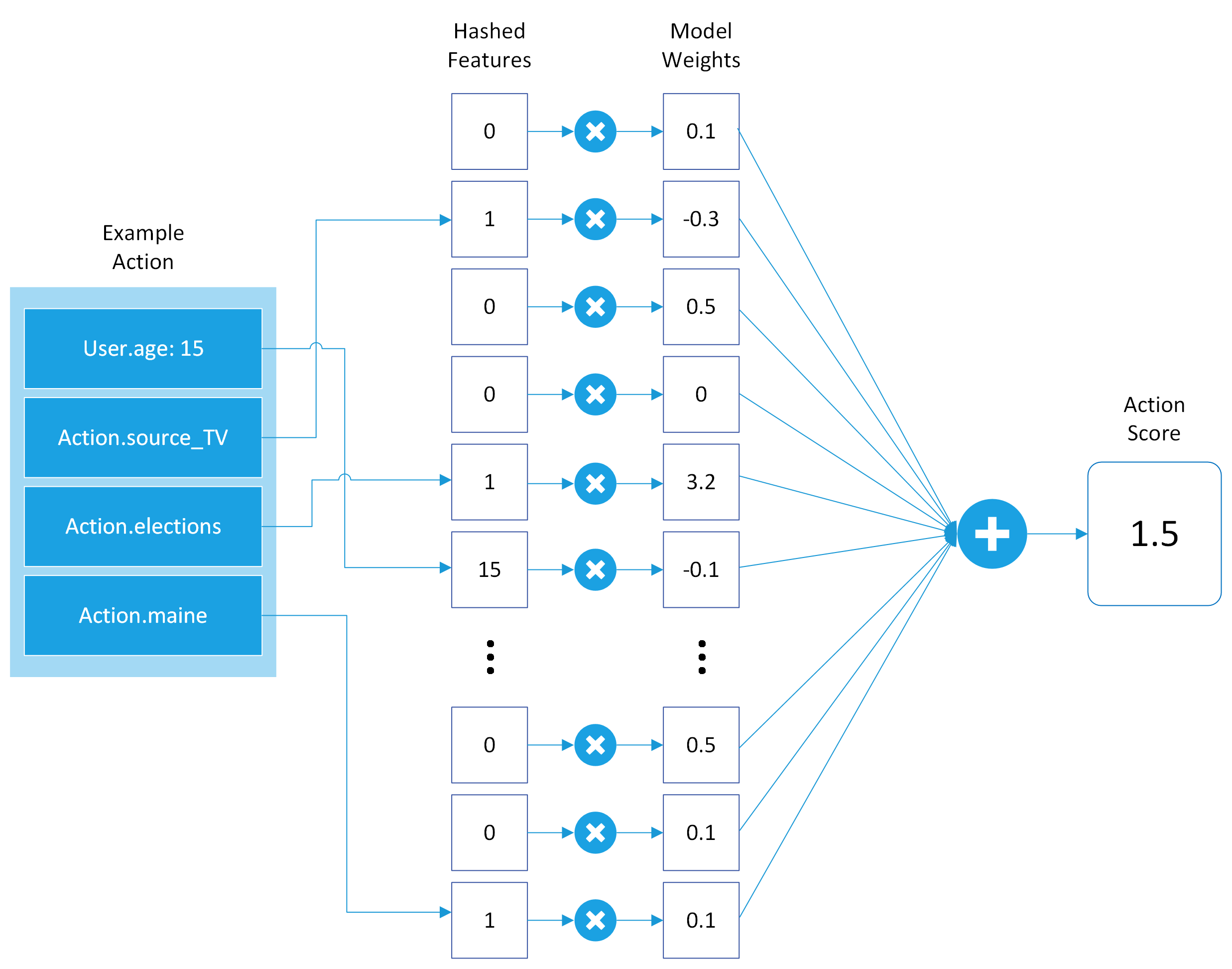 Basic Vowpal Wabbit model architecture
Basic Vowpal Wabbit model architecture
This is just a simple linear combination of the features passed in, which is very fast to compute, optimize, and understand, but this means it can’t learn a model that’s a combination of input features. For example, if users in Maine who watch TV react well to an action, but not users who watch TV in other places, this model cannot capture that. It can only capture features of users in Maine on the whole, and features of users who watch TV on the whole, but not together.
Improve Model Features with --quadratic and --cubic
The default model architecture is almost never going to give good results, so you need to tweak the the model architecture to allow it to learn a better estimator. One of the simplest yet still powerful ways to do that is via the --quadratic or -q option. This option allows you to generate new features from every combination of features in namespaces.
The syntax to do this is pretty strange, you need to take the first letter of the name of each namespace and pass a 2-character string after -q to indicate which 2 namespaces to mix together. In our case above where we have an Action namespace at a User namespace, we could mix them with -q UA. We could even do -q UU to mix the User namespace with itself. You can also pass -q multiple times with different combinations of namespaces. You can use : to indicate everything across all namespaces. So -q U: would mix the User namespace with everything across all namespaces.
If you want generate features by mixing 3 namespaces together, you can use --cubic like --cubic UAC or --cubic UUA. If you want to mix more than 3 namespace permutations together, you can use --interactions to specify any number of namespaces to mix together. For example --interactions UAXBY to mix 5 namespaces together.
I think that if there are numeric features, only the value of the last feature in the namespace will be used as the numeric value, so if you have a namespace with a lot of numeric features it should probably go last. (I could be wrong about this!)
There’s a list of more feature enhancement settings available in the VW Wiki.
Neural Networks with --nn
In addition to mixing features together, you can a use simple feed-forward neural network as the model instead of just a pure linear model with the --nn param. The depth of the neural network is specified using an int, so --nn 2 would be a 2-layer neural network. There are a number of options available to further tune the neural network architecture in the VW Wiki.
Evaluating Different Model Settings / Params
Vowpal Wabbit is extremely fast to train, which is nice because it makes it easy to test out lots of different model settings using offline policy evaluation (OPE). There’s a good tutorial on how to do this on the vowpal wabbit website, so I won’t go into too much detail here, but I found offline policy evaluation essential to figuring out which model params to use to get good results.
One thing that confused me at first was that OPE outputs what it calls “average loss”, but really this means “average cost”. If you use negative cost like I did, then “average loss” will be negative. In all cases, the lower the number for “average loss” the better, even if it’s negative.
Make sure to try out lots of different settings for things like learning rate (-l) and number of passes over the data (--passes) as well. I also found --cover 1 seems to work much better than --cover 3 for some reason.
In Python, I found that you can use the vw.get_sum_loss() method after doing a test run and dividing by the number of test samples to get the “average loss” which is output by the CLI method, if you want to do this in Python rather than using the CLI.
Python Quirks
There are a number of strange quirks with the Python wrapper. It doesn’t always seem to accept examples in the same format always. For example, for .learn() and .predict() you can pass an example directly, but for some methods like .audit_example() you need to parse the example into multiple parts using vw.parse() first.
For JSON input, you need to run the Python dict examples through json.dumps first before passing to vowpal wabbit
There are also methods that just print stuff out to stdout instead of returning a value which is obnoxious. For instance it’s not currently possible to get the results from --audit into a string in Python for further processing. If you don’t pass --quiet, the python library will just print stuff to stdout and stderr as it runs. As far as I can tell, there’s no good way to get this data into a more natural Python interface.
Python Tips
I found it’s easier to just write data to temporary files on disk and train via passing in a reference to the training file rather than passing training examples in Python, due to some of the quirks around how the Python library handles example parsing. This of course assumes that the data for learning isn’t so large that it can’t fit into memory or on disk. The code might like something like the following:
import vowpalwabbit
import json
from tempfile import NamedTemporaryFile
def create_and_train_vw(json_examples):
file = NamedTemporaryFile("w")
file.write("\n".join([json.dumps(ex) for ex in json_examples]))
file.flush()
vw = vowpalwabbit.Workspace(f"--cb_explore_adf --json --quiet -d {file.name}")
file.close()
return vw
When you call .predict() on a vw instance, you’ll just get an array of probabilities mapping a probability to every potential action you could take. To use the output from vowpal wabbit for prediction, you’ll need to sample the predict results according to the probabilities it returns, like below:
import random
def sample_prediction(action_probs):
"return the index of the selected action, and the probability of that action"
[selected_index] = random.choices(range(len(action_probs)), weights=action_probs)
return selected_index, action_probs[selected_index]
action_index, probability = sample_prediction(vw.predict(ex))
Getting Help with Vowpal Wabbit
The documentation for Vowpal Wabbit leaves a lot to be desired, so you’ll likely need to venture outside of the offical website docs while trying to use the library. There’s an official Wiki on Github for VW which has some good info, but it also has a lot of gaps and some of the pages are incomplete. I found it helpful to ask questions in the VW Community Gitter, as there are people there who respond quickly to any questions. There’s also some good info in Stack Overflow as well. As a last resort, I also found posting issues on the VW Github page to also get a lot of in-depth responses from the devs when I thought something looked like a bug.
Go Forth and Wabbit!
I’ll keep updating this post as I learn more. If you see anything that’s not correct, please leave a comment to let me know and I’ll update it!